Developing digital products is an adventure, and the journey is as important as the destination. When it comes to crafting apps around GenAI functions, the thrill of novelty also joins us.
Let’s take a look at how the Appic by Hiflylabs team worked with the in-house AI experts to create a multi-agent system to provide real-time insights from complex datasets!
From planning the adventure to reaching the peak, we’ll cover building compound AI workflows, how we designed and developed them to be interactive and explainable, and why Databricks Apps was our choice of backend to build this journey around.
Making AI Work
With the introduction of LLMs, language itself became a new interface. But when someone says “artificial intelligence”, you are not picturing a chatbot, rather, people expect a fully capable system.
AI agents can meet these expectations. Agency means a capability for independent action and autonomous decision-making. As such, AI agents are currently the most useful form of GenAI integration.
LLMs are equipped to tackle the task of processing unstructured data (which makes up around 80% of all data out there!). Agents enable their automation, but how users interact with the agents and the results of their queries is a challenge for digital product developers.
According to LangChain’s recent survey, they’re most commonly used in tasks that are either time-consuming by themselves, or everyday menial jobs. Ever had to comb through dozens of pages in your work to find a tiny relevant detail? Research and summarization are the top agent use cases. They’re closely followed by personal productivity/assistance such as helping you schedule your day, and customer service tasks, including faster response times and more effective troubleshooting.
Taking it one step further, multi-agent systems allow you to assign hyper-specific tasks to various models, and make them cooperate for more accurate outputs, more efficiently.
Think of the Financial Services industry, for example. Extracting insights from a combination of just a bank’s transaction log, market trends and other external economic factors takes just a handful of minutes, contributing to the optimization of the bank’s product range, creating personalized offers, and more.
We worked on multiple projects pertaining to the consolidation of large amounts of business data into easy-to-handle formats for the financial industry. Here’s a quick rundown of our learnings about the process, from UX/UI to frontend and backend development!
UX/UI Design - A Reliable Guide
The biggest difference between “traditional” UI design and that of apps built around a system compounded from multiple LLMs is the need for extra transparency. This is especially true in high-stakes industries such as healthcare or financial services, but explainable AI principles will go a long way in any sector.
Due to the limitations of language models—like unreliability, and hallucinations—user trust can only be expected from being able to see what goes on under the hood. Which sources did an agent use? Where did it pull information from? How did another agent process that data? Or on the more practical side of things: how far along is the agent in the process and how much longer will it take?
Our goal was to track every action and show it all to users. Every workflow contains validation steps as well, but if any error still gets through, the human in the loop can easily spot where the misstep happened.
In a typical multi-agent workflow, for example, users can ask the system to further clarify or adjust its process, such as:
- Rephrasing their prompts
- Directing the AI to specific information sources
- Instructing it to re-evaluate its answer
However, users might want to intervene at different points, and this is where context-aware interactions come into the picture. UX/UI teams need to focus on designing features that guide the user along their journey as if it was intuitive.
The most significant consideration is handling user inputs and model outputs flexibly. Language models are non-deterministic, and user needs can change on a whim during a session. Follow-up questions, edge use cases you couldn’t have thought of during testing, and errors slipping through are all but coded into this tech. This is why letting users directly interact with workflows within the compound AI system, pivoting them, and giving feedback in real time is a must.
At the same time, as the tech’s full capabilities broaden, you might have to think ahead. This includes:
- Scalable UX/UI: Creating a system that is easy to build on later down the line when new features are released
- Preliminary issue mapping: Exploring business challenges the product is supposed to solve more thoroughly. You might know an answer/use case your client is yet unaware of.
Frontend - The Master Cartographer
If UX/UI plans the route, it’s the frontend’s job to create the map where our journey takes place.
Enabling context-aware interaction mentioned above drove the way we approached frontend development. LLMs output a wide variety of formats from text to tables, graphs and code snippets. As opposed to web interfaces of leading LLMs, in the case of custom-built web apps where we call the OpenAI API for example, we need to build the environment for our desired visualizations.
Our go-to pipeline looks something like this: we generate Markdown (its conciseness creates less room for error, and its readability helps human-in-the-loop development) and then translate it into HTML. Afterwards, the HTML creates the basis of our custom web interface.
Due to existing component libraries being few and far between, we created our own tools for these projects. A custom renderer handles the LLM’s array of output formats accordingly, built on generic components so that the renderer remains flexible.
Additionally, while popup menus with related actions when highlighting parts of the output have existed before, doing this in an environment where the output’s format is not predetermined is a whole new challenge.
Tailwind CSS, while definitely not a new tool, allowed us to create styles for our new libraries quickly, making the development that much more efficient.
On our latest project, we also had dashboard requirements that were less non-deterministic, and there were parts of the home page of the app where we wanted to showcase analytics results consistently in the same format. The parts of the dashboard separate from the chat interface’s functionalities were dynamically drawn with D3.js, an open-source library we used for .svg generation.
As opposed to being limited to legacy frameworks and codebases, we had the opportunity to use cutting-edge tech that developers are usually not able to try on enterprise-level projects, such as Angular’s latest release. Compared to using previous versions, we managed to avoid potential compatibility issues, as well as the cumbersome compliance process caused by multiple providers.
As a bonus, this allowed us to look forward outside of the project’s scope. The development directions and approaches these new versions of tools required will be an advantage in future projects as the tools become more widespread.
Backend - The Trusty Backpack to Carry the Necessities
When deciding on service providers for data management and the AI model, we were faced with a question.
Do we go the “traditional” route of multiple ecosystem providers (such as AWS+Databricks), or try a new platform to bring it all under one roof?
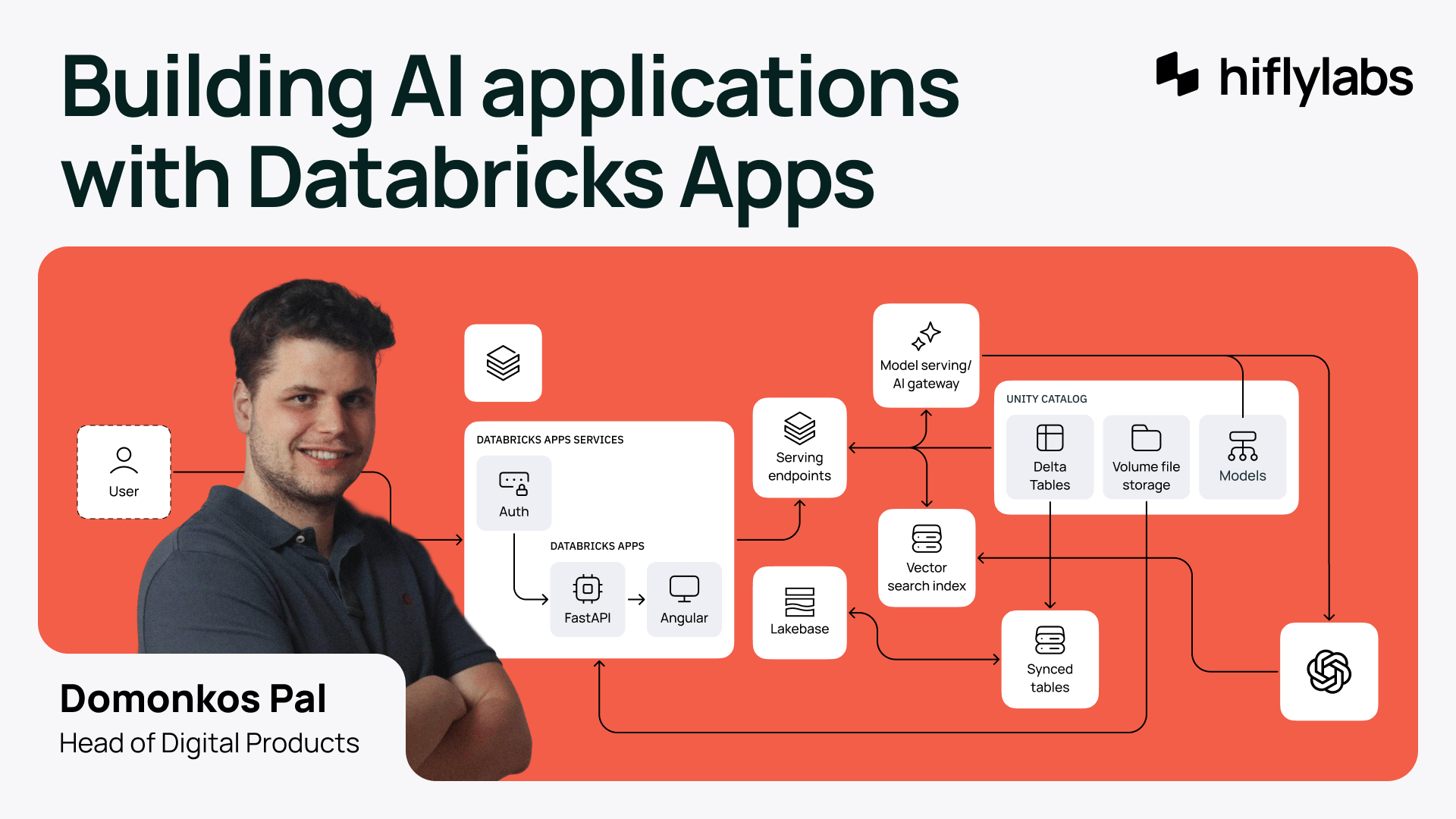
With Databricks being a leading platform for ML/AI workflows, utilizing their new Databricks Apps platform is a no-brainer.
We had the opportunity to work with Databricks Apps in its pre-release version (now in Public Preview), and we were impressed with how it handled AI, data, and apps on the same platform. This means less time spent on approving providers and checking cross-compatibility, as well as a load of other benefits.
- Security, authentication, and data governance are built-in. Security keys and tokens are handled by Databricks, no time wasted setting up firewall exceptions.
- Fast deployment and custom code compatibility. We hosted Python + Angular apps on a FastAPI backend, with SQLAlchemy as an ORM, but other solutions work just as well.
- All under one roof. Monitoring and analytics are simple, and you have easy access to all the data needed for price calculations. No more mix-and-matching of various facets, like when you’re deploying to AWS + Databricks combined.
- Easy AI integration. The AI’s chat function ran on serving endpoints within Databricks Apps, making calls easy.
On top of these features, the future potential of Databricks Apps makes the solution even more appealing. We’re looking forward to seeing features such as detailed configuration, multi-level authentication, and transactional DBs.
Conclusion
Despite being a relatively new tech, AI models are already powerful enough (and they’re getting better with each new version), but to maximize their potential, a mindset change is required.
Developers need to find more effective applications. We need to build an interface to communicate with it in a truly efficient fashion and design custom software around it to function reliably in large-scale enterprise settings.
Instead of focusing on more powerful models, we should work towards feature engineering and create workarounds for limitations (hallucinations, etc) to further the currently available technology’s maturity. (An activity that can be referred to as “unhobbling”, a term from Leopold Aschenbrenner’s Situational Awareness essay.)
Software built on multi-agent systems are the right step in this direction.