
CTO Perspectives: An AI Reality Check
If you're in sales or management, it can be tough to tell what matters from noise. Here’s our reality check for the 2025 tech market, covering where AI truly stands today.


Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.
Sometimes the best decisions feel like the worst ideas at the time. Like betting your entire project timeline on a platform that just launched its first preview version. What could possibly go wrong? But here's what happened when we took that leap with Databricks Apps.
This is a story of a year-long journey building apps on Databricks—the good, the lessons learned, and the reasons why I chose it in the first place. And why I'd make the same decision again.
This is a real application, with real users and real deadlines. The actual project and its data are confidential, so I’m going to talk about it metaphorically. Let’s say it’s an AI-assisted baseball recruitment platform.
The client approached us with a very specific request.
We need an AI application with the following requirements:
And all that had to be built in 30 days.
Sounds easy, right? So, how should we approach this task?
Databricks and AWS
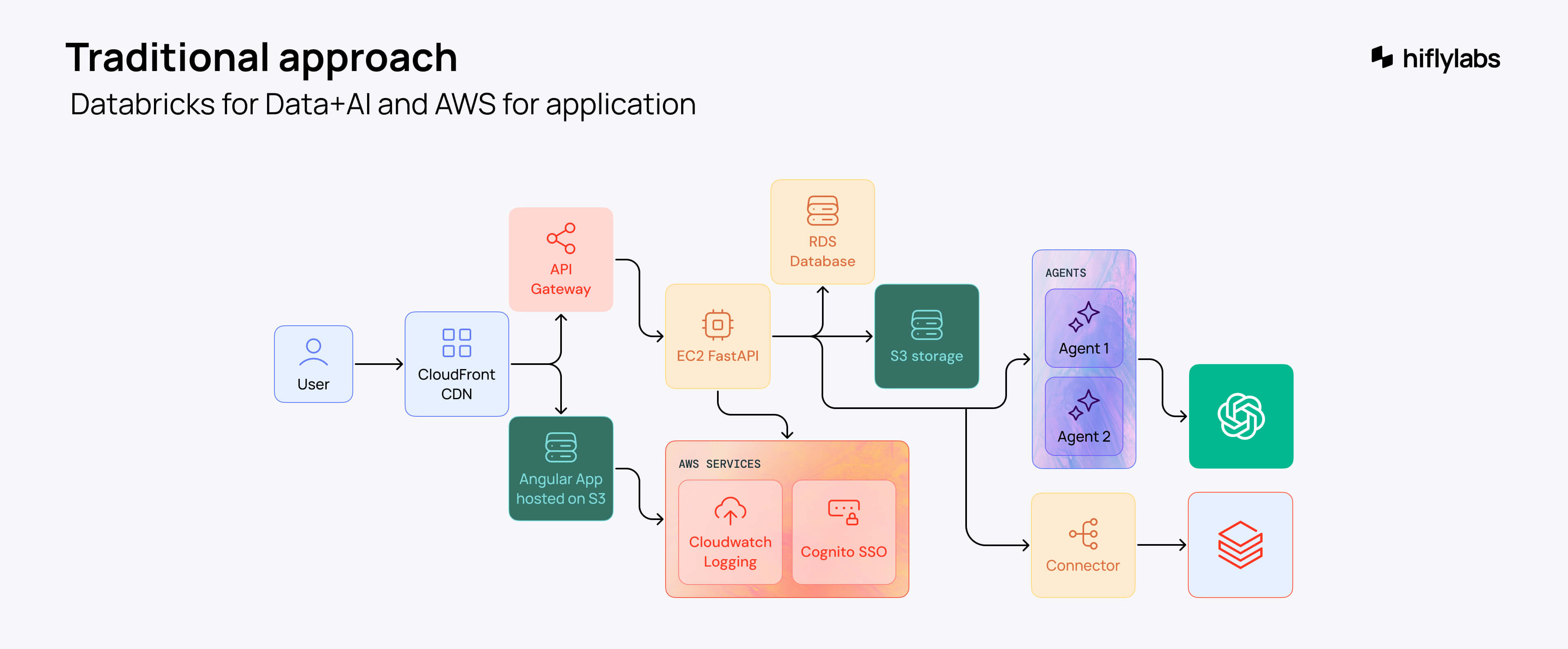
We started with the classic approach and went for a well-known cloud provider—AWS. Just like any other team would. It’s tried and tested and has been an industry standard for a decade. However, we quickly ran into obstacles:
All things taken into account, the architecture would work like this:
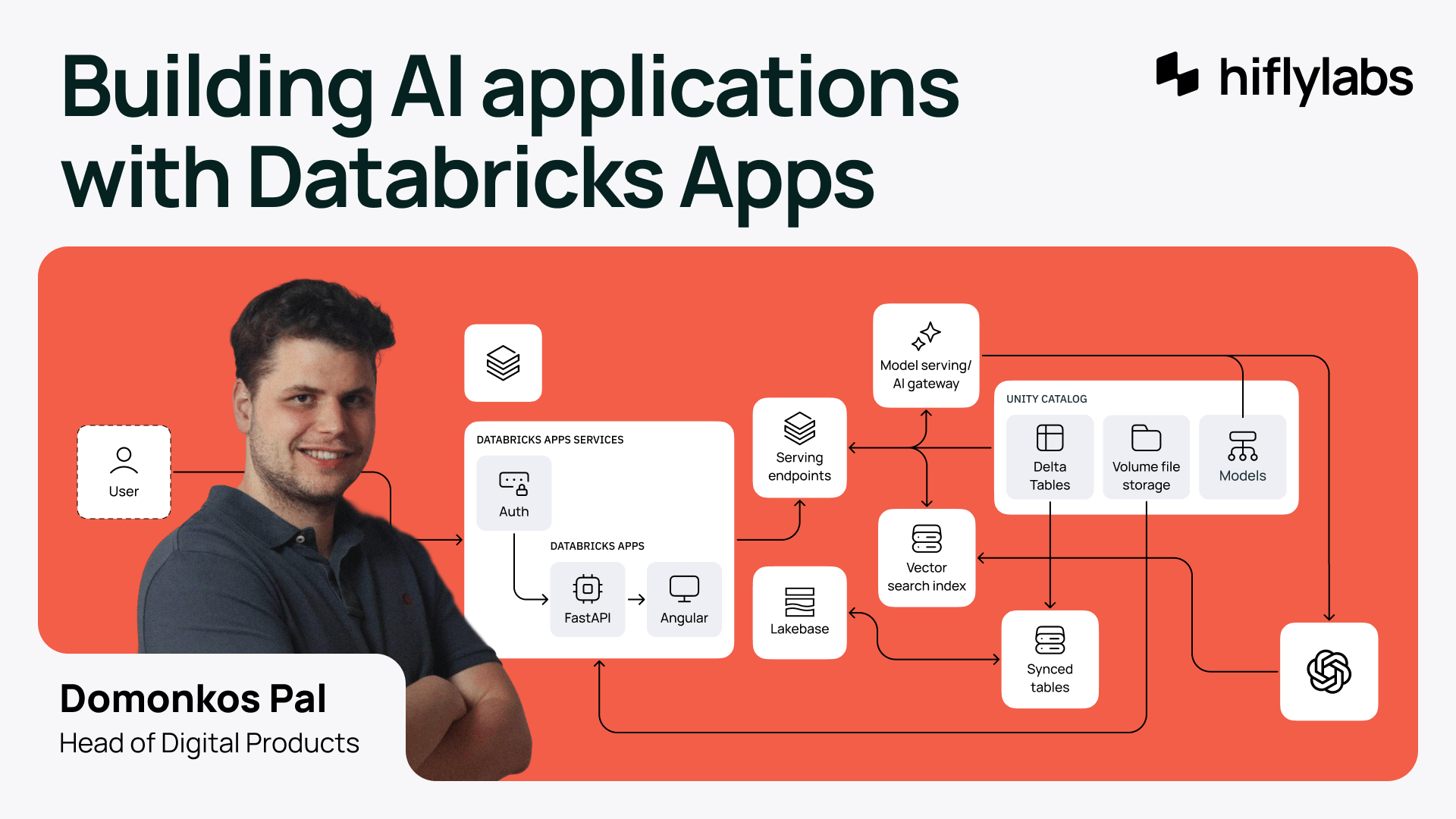
Just then, an email with a big promise dropped into my inbox. Databricks Apps—an integrated AI app development environment with serverless hosting, built-in security, authentication, and data governance. Deeply integrated into Databricks, it was close to our existing data, Unity Catalog, and AI gateways.
That was exactly what we needed at that moment. If only we had a time machine to have it in GA and ready for production.
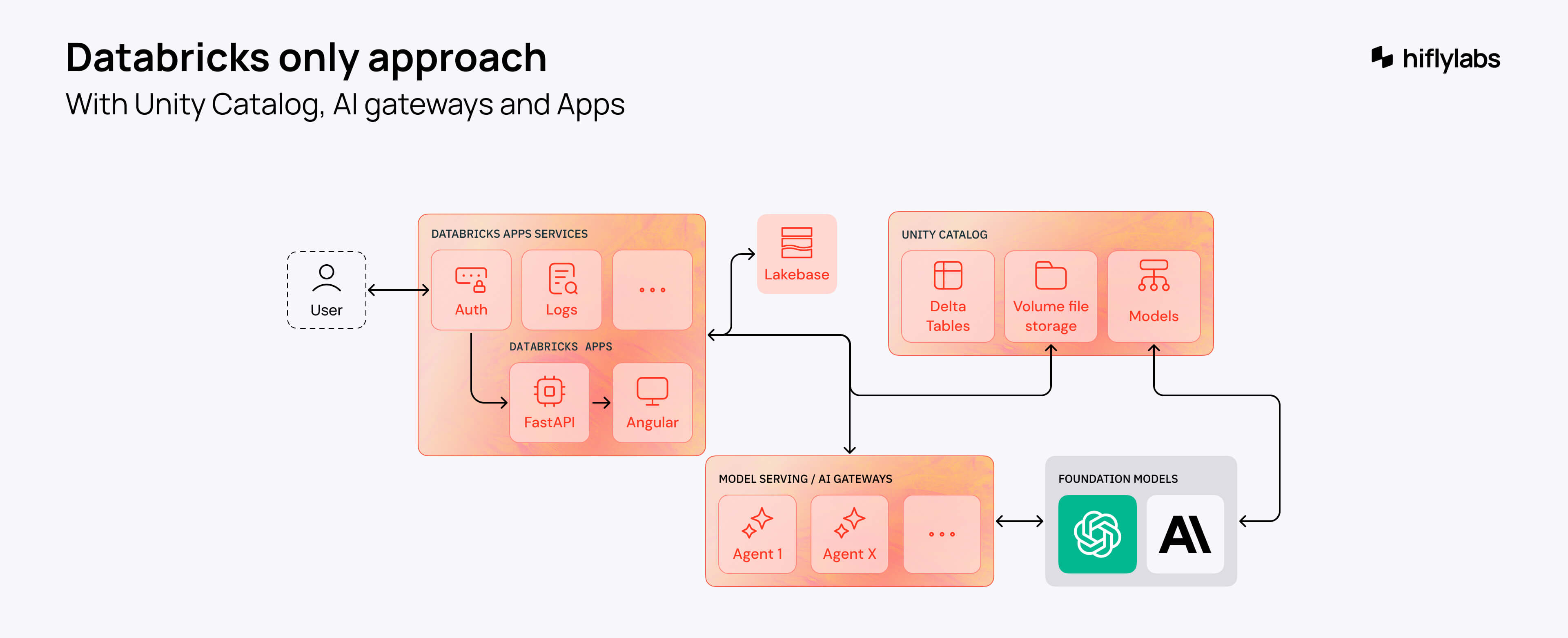
Databricks only
I have to admit, it was a bit of a gamble. But we bet on Databricks Apps from day one, even though it was still in preview.
I'm not saying AWS wouldn't have worked. However, it was clear that with a Databricks-only architecture and built-in boilerplate features, we could reduce development time by at least two weeks—impressive given that we only had 30 days in the first place.
You know how we developers are when it comes to trying out new shiny tools. But of course, with every new tool comes new tool drama. So I braced myself for unstable deployments and random crashes without proper traces.
Yet, remarkably, Databricks Apps not only saved us late-night headaches. It went so well that it gave us extra time to add more features to the original scope.
Was everything nice and smooth? Of course not.
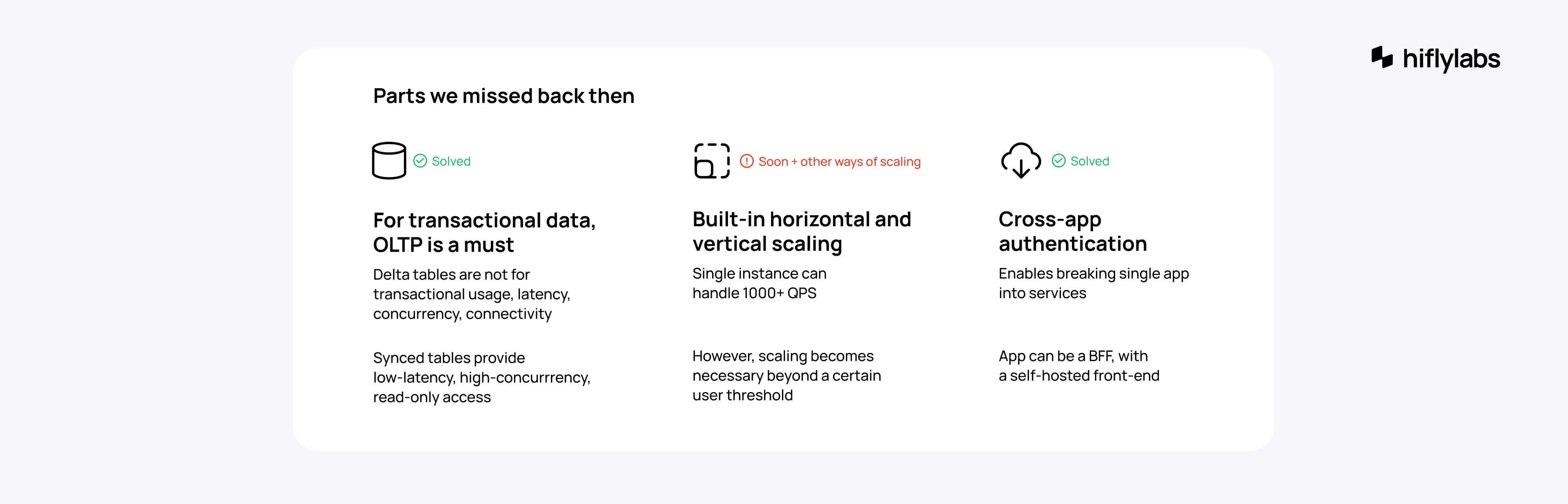
For one, we struggled with the database. Lakebase wasn't available back then, so we had to rely on Delta tables for transactional data. One of the first things you learn when you study IT is to avoid this pattern. This led to slower transactions and connectivity issues.
Another problem was the lack of built-in scaling. So we had to design our architecture to cover this. Fortunately, Databricks provides powerful services for heavy computing and clusters below the application layer. In the end, optimizing our app to be as thin as possible paid off significantly.
For instance, someone accidentally deployed an ML model execution into the backend app. You can imagine the chaos it caused. No surprise Lambda is generating so much revenue.
Scaling is only good if you do it properly.
Since then, both challenges—OLTP and scaling—have been completely solved. I’m going to show you how.
This is the data architecture we used.
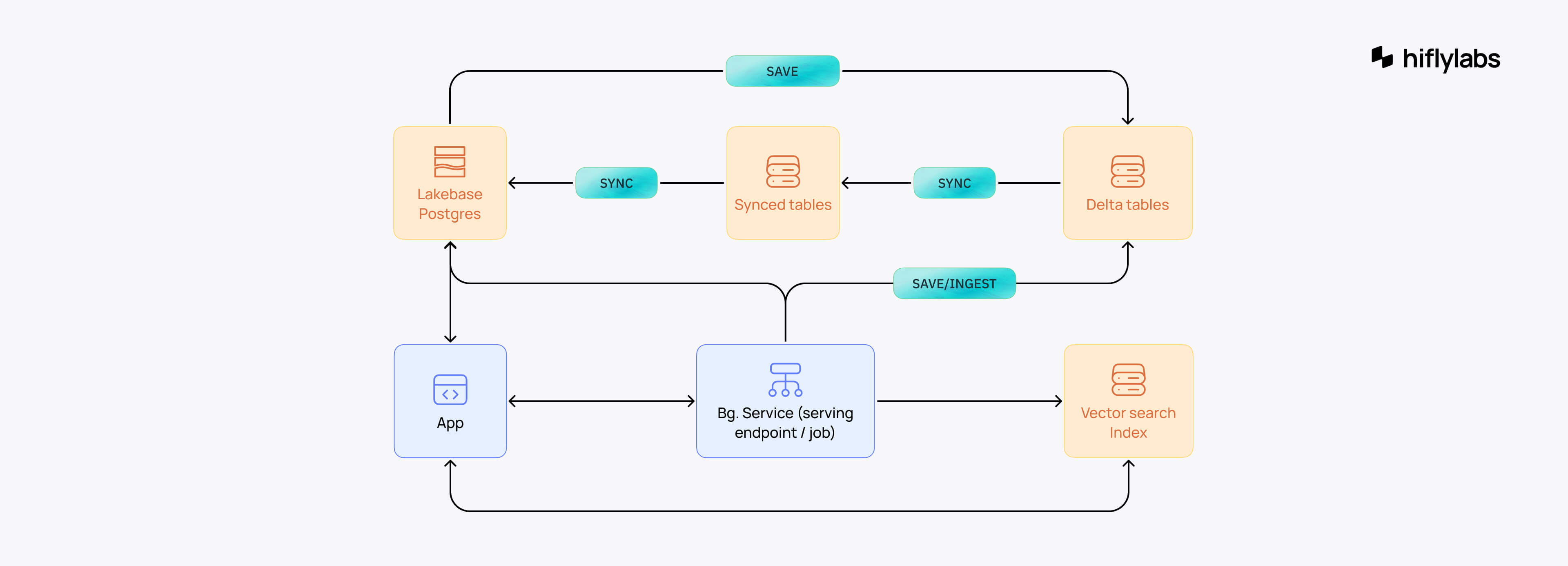
We synchronized operational and business data to Lakebase OLTP through synced tables, ensuring low latency and high concurrency. Persisting data into the Delta table was typically managed through background services or pipelines. Initially, we had similar methods for Vector Search Index as well, however, it currently handles 1000+ QPS.
Serving all our data through OLTP supported our scaling strategy. It can handle thousands of queries simultaneously, with dozens of open connections.
One of the most remarkable highlights for us was the Databricks CLI for Apps and overall CI/CD capabilities. If you have worked with AWS, Azure, or GCP, you would appreciate how fast and easy it is to set up an application from scratch on Databricks. You can do it in just a few minutes:
And voilà! Integrate it with GitHub Actions, and you will have a production-ready CI/CD pipeline in minutes. You can find samples in the GitHub Repository to see it in action.
Little did we know that the client’s ambitions went beyond an MVP app.
For the next phase, we had to build a complete self-service AI portal. So that baseball scouts could have everything done in one application without reaching out to other platforms. It should be able to compete with mature AI SaaS and:
At this point, we had to decide whether we had to migrate or not. Databricks Apps was ideal for building a custom app for an MVP. But would it work at scale?
Back to where we started, we designed this beautiful architecture once again. So many boxes and arrows, it almost looked like a subway map.
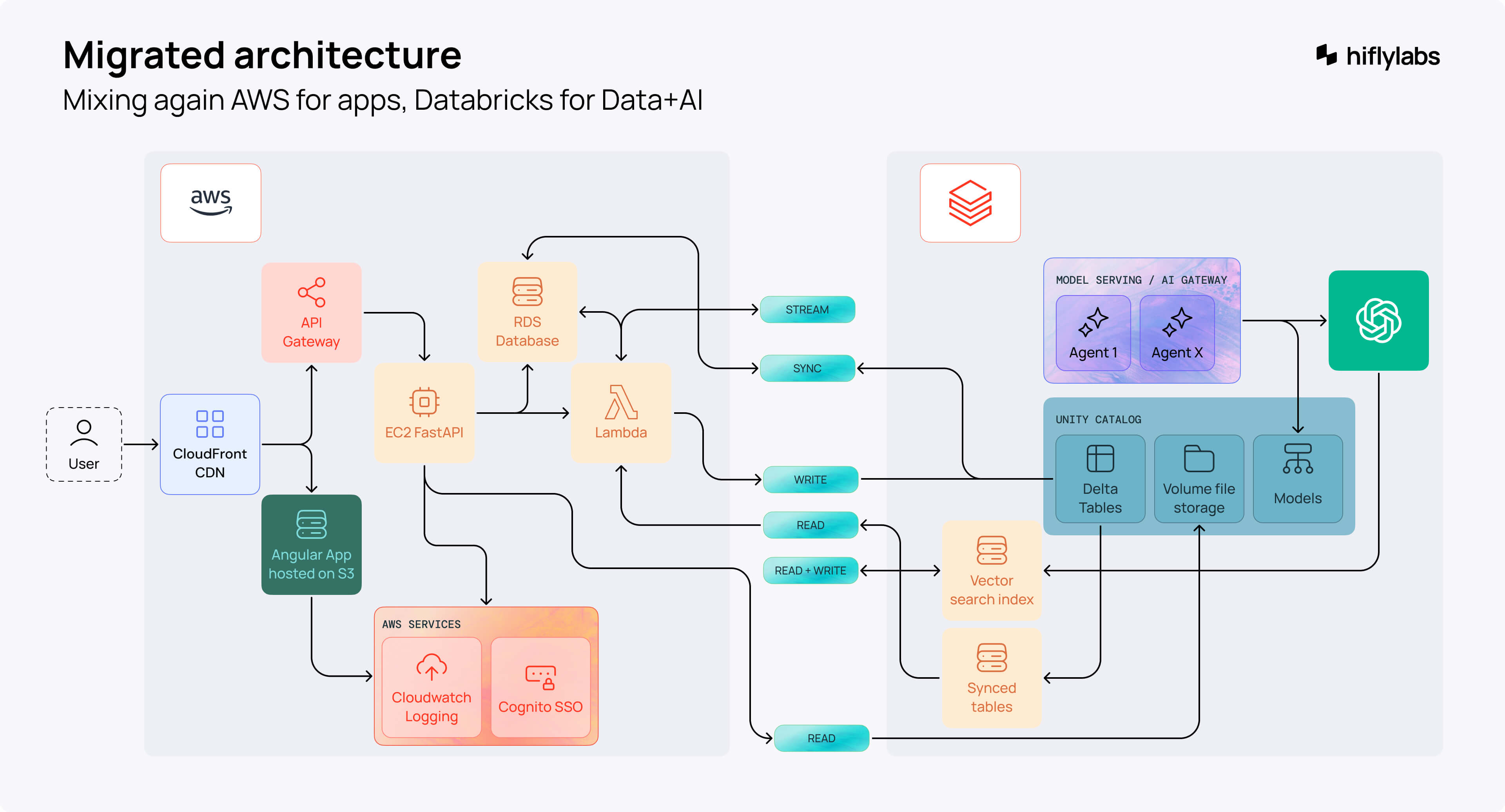
Before moving on with this scenario, we talked to the team from Databricks. They suggested that we try to build the architecture on Databricks. It would scale using only Databricks services and look like this.
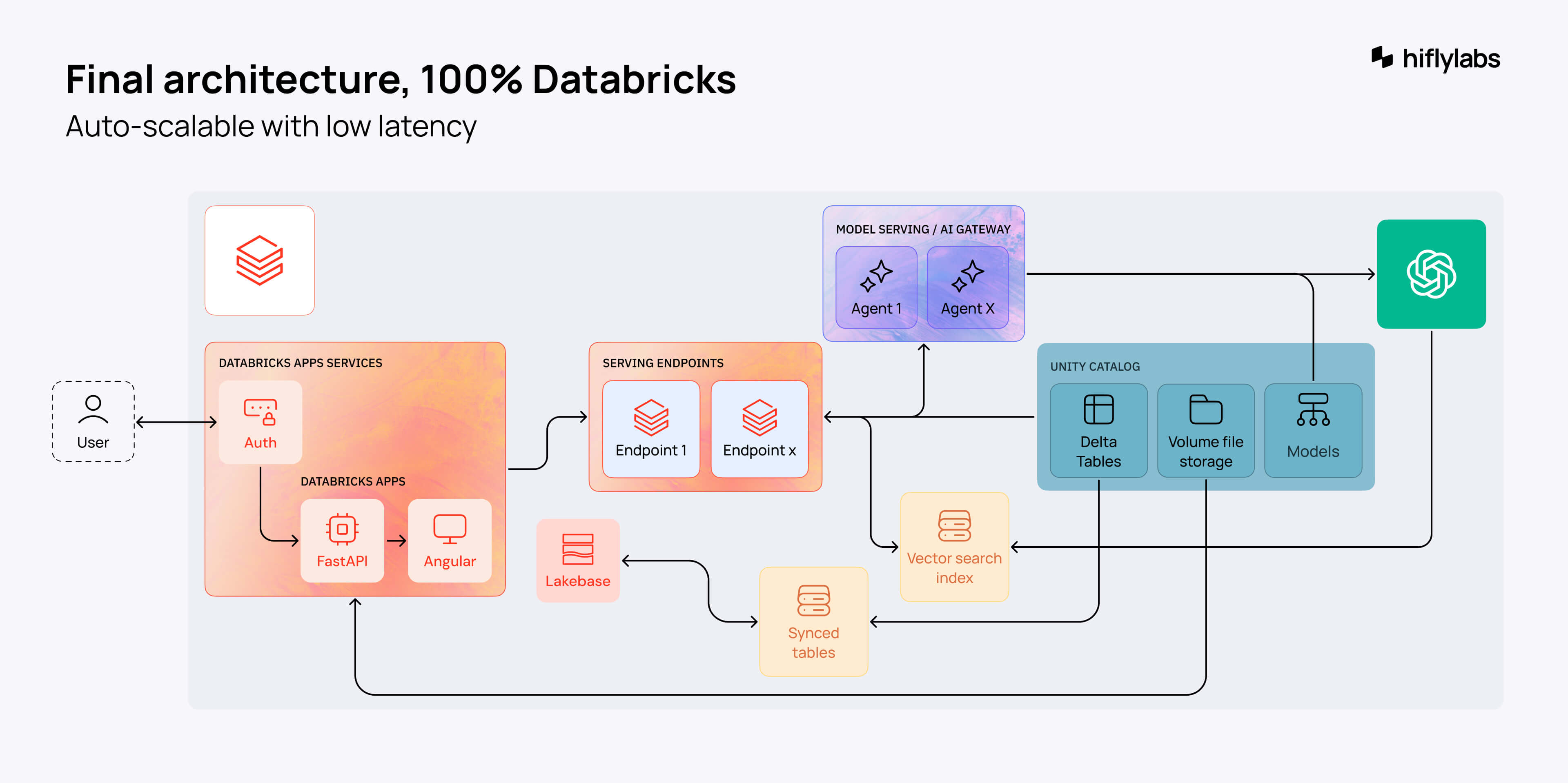
Although it seemed promising, in the background, I spent a couple of nights preparing for a possible migration, just in case. But it wasn't necessary.
That said, in the process, I discovered another important advantage. The Databricks SDK is so well-designed for migration scenarios that we’re not locked into the Databricks Apps platform. We had complete freedom to stay or to move.
To make the right decision, we carefully listed the advantages and disadvantages of both approaches.
Benefits of migrating to AWS
Benefits of staying on Databricks
An important drawback in this scenario is that, up until now, the strengths of Databricks Apps mostly stand out when building enterprise-level internal applications.
But the most crucial question remained: Can we actually scale a 100% Databricks application?
Turns out we had several options for scaling.
I’m the kind of person who believes it when I see it. So, I tested our most critical tasks involving multiple AI gateway queries, read/write operations to OLTP databases, Delta tables, and a Vector Search Index. Mind that these are my own measurements and not official numbers.
Did the client make the right call to build instead of buying? After all, most of the features we implemented in the Databricks custom apps were already available elsewhere.
Here are a few important aspects to consider before making this choice:
Plus, you spare yourself growing license fees as you scale up. And if you already use Databricks for data and AI, you gain a lot by extending with the Databricks Apps platform.
Nothing is impossible with Databricks. We thought building a production-ready AI app in 30 days couldn't be done, but here we are.
So stop overthinking your architecture and start building. Get my GitHub repo with (nearly) everything I’ve just described for a head start. Because sometimes the best way to learn is to steal.
Or reach out to me directly if you want to skip the trial-and-error and get straight to building something that actually works.
Looking for a certified Databricks partner who can get you to production faster than your competition?
This blog's contents were originally presented at Databricks Data + AI Summit 2025 in San Francisco.
Watch the recording on YouTube.
Explore more stories
CTO Perspectives: An AI Reality Check
If you're in sales or management, it can be tough to tell what matters from noise. Here’s our reality check for the 2025 tech market, covering where AI truly stands today.

Auditing Webshop Listings: How We Turned BigQuery into an AI Data Quality Engine
E-commerce platforms struggle with mismatched product titles and images. We built a solution for a Kaggle challenge that uses BigQuery and Gemini to act as an automated catalog auditor, classifying millions of listings for consistency and providing actionable insights to improve data quality.

AI Agent Governance: What to Prepare for as AI Enters Your Stack
AI agents are here, and they’re not just suggesting actions. They are taking actions as well, on their own! The question is: who’s governing them?