Bogged down in a Data Swamp? Transform chaos into clarity for informed decision-making. Uncover the causes, consequences and solutions in this article.
As data floods into organizations, maintaining order is pivotal. Proactive data governance not only preserves data value, but also unveils transformative insights. This article explores how Data Lakes can devolve into Data Swamps without regular quality checks, metadata upkeep and adherence to retention policies, offering strategies to safeguard data-driven initiatives.
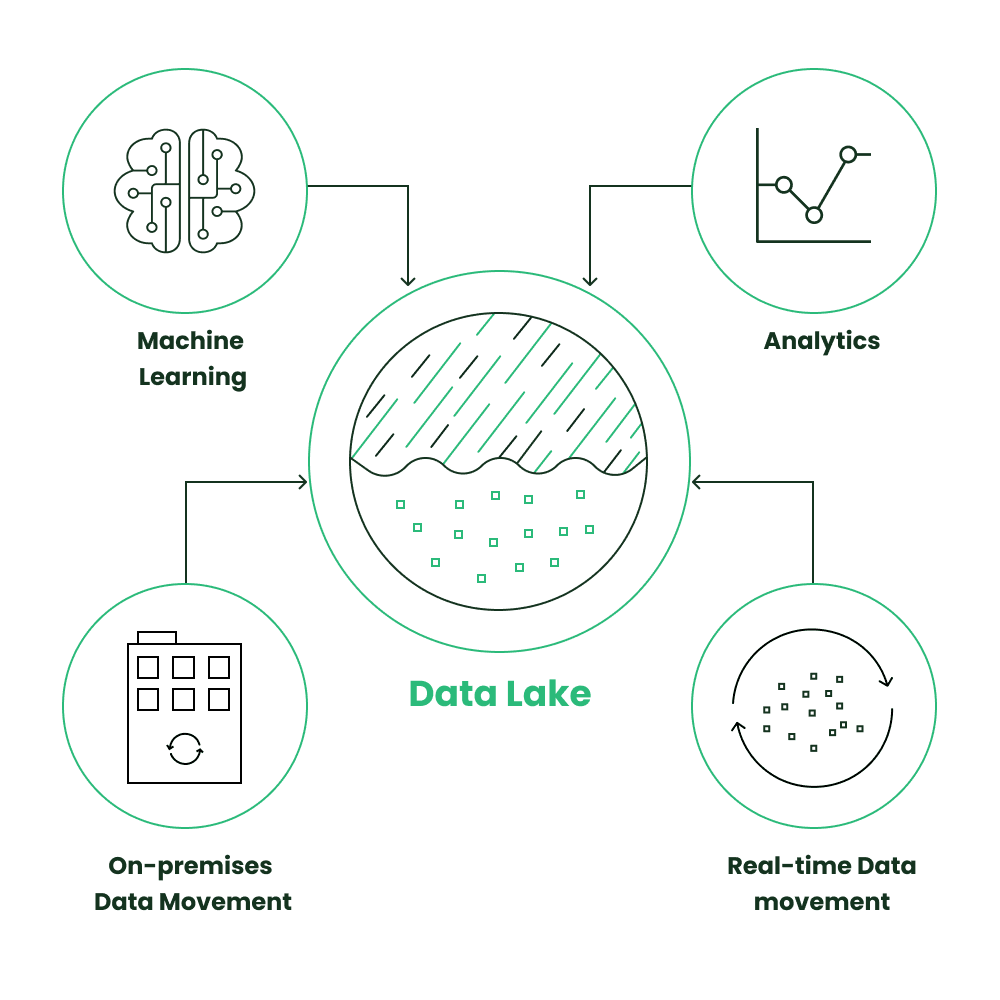
Quick Recap: the Data Lake
Data Lakes create schemas during data reading, prioritizing flexibility over structure, which enhances agility. They defer processing until data retrieval and are built for cost-effective storage. Data Lakes are a recent technology without strictly defined designs. They can store diverse, raw data in any form, whether structured or unstructured—encompassing text, audio, video and images. Unlike Data Warehouses, Data Lakes don't adhere to strict data governance, yet we also stress proper data management to prevent them from becoming Data Swamps.
Telling a Lake from a Swamp – Unstructured Data vs. Complete Chaos
Where’s the line between the two?
Data Lakes are centralized repositories that allow you to store both structured and unstructured data at any scale. You can store your data as-is, and still be able to run different types of analytics.
The problems start when you realize that the most important part—analytics—is somehow impossible.
This can happen when the data is partly:
– Inaccessible or segmented into silos that need arbitrary permissions
– Missing metadata; proper file names, formats, dates, sources, etc. – Lacking in integrity; data governance should ensure adequate data quality
When the above negative attributes hinder analytics beyond repair, we can solemnly conclude the presence of a Data Swamp.
Instead of deriving valuable insights from clean and reliable data, these sorrowful bogs only yield disappointment, confusion and unreliability.
As opposed to accommodating expanding data needs, Swamps grow unwieldy due to their absence of proper organization and scalability. Rather than promoting collaboration across teams, they inadvertently foster data silos that hinder effective communication and collaboration.
Lastly, whereas structured Data Lakes (like Delta Lake) can enable advanced analytics techniques like machine learning and artificial intelligence to extract profound insights, data swamps inhibit the application of these advanced techniques due to the subpar quality and structure of the data.
Data Swamp vs Data Team - Prevention Is the Best Intervention
The real challenge is the proper "operation" of our data regulations. Automated quality checks and educating people in the workforce are essential, as is understanding the number of loopholes and who can access and manipulate them in the context of data governance. With that in mind, let’s skim through 7 best practices in Data Swamp prevention and repair:
7 Tips to Prevent a Data Swamp
Establish a robust data governance framework and a well-defined data strategy from the outset. Define data ownership, data quality standards, access controls and data lifecycle management policies.
Plan the data architecture carefully, including data categorization, modeling and integration strategies. Ensure data is organized and structured from the ingestion to the user end.
Implement a metadata management system to capture and maintain essential information about the data, promoting understanding and discoverability.
Set up data quality checks and validation processes to ensure accuracy, completeness, and consistency.
Prioritize data security measures, such as encryption, access controls and data masking, to protect sensitive data from unauthorized access.
Educate employees about data management best practices and foster a data-driven culture.
Regularly review data management practices, data quality and data governance policies to identify areas for improvement and implement changes proactively.
7 Tips on How to Fix a Data Swamp
Assess the extent of the data swamp, identify redundant and irrelevant data, and clean up the data repository. (Easier said than done—draining a Swamp is often impossible, so make prevention a priority!)
Organize the remaining data into meaningful categories and establish a proper data architecture.
Reconstruct metadata to provide context and information about the data in the newly organized environment.
Apply data cleansing and data quality processes to improve the accuracy and reliability of the data.
Address data integration challenges to ensure data from different sources can be combined and analyzed effectively.
Don’t forget that in some urgent cases, quick fixes like data deduplication, metadata enrichment and immediate security measures can be implemented but these are only symptomatic treatments.
Sometimes the solution is taking one step back, taking a deep breath, and considering a complex reformation of your data architecture and migrating data from the Swamp to a well-structured Data Lake or Data Warehouse.
Why There Are a Lot of Data Swamps These Days
Organizations are gathering massive amounts of data from various sources, but often without a clear plan for utilization or without proper governance in place that could ensure efficient data management.
Thanks to the Modern Data Stack, cloud computing solutions and storage services, large volumes of data have become easier and more affordable to manage. However, this convenience can lead to a jumble of unorganized data if we take governance too lightly. As a result, many organizations struggle with their troves of data that hold untapped potential.
Bogged Down in a Data Swamp? Ask For Help!
A Data Swamp does not come about by design! And once you are stuck in there, only with significant effort, data cleaning, restructuring and the implementation of robust data governance practices can it be transformed into a more organized and usable environment. This transformation requires significant effort, time, and resources. Moreover, it is essential to implement ongoing data management practices to maintain a Lake's usability and prevent it from regressing into a Swamp again.
The good news is that we at Hiflylabs can help with many years of experience in different data architectures, and the migration between them.
How is AI transforming various sectors within finance, from banking and investment services to insurance and fintech? We’re highlighting both vertical and horizontal use cases.
Databricks Apps boosts the development of AI-enhanced apps to a level never seen before, and we have firsthand experience with its pre-release version!
Automated Databricks provisioning on Azure with Terraform and Python scripts—transitioning from PoC to production, overcoming challenges, optimizing deployment.
We want to work with you.
Hiflylabs is your partner in building your future. Share your ideas and let's work together!