
AI Agent Governance: What to Prepare for as AI Enters Your Stack
AI agents are here, and they’re not just suggesting actions. They are taking actions as well, on their own! The question is: who’s governing them?



Discover how to create and automate Databricks environments using Terraform on Azure. Learn best practices for scalable, consistent data infrastructure deployment across global markets.
By the end of this guide, your Terraform project will be able to bring up a Unity Catalog enabled Azure Databricks Workspace, with repos imported and clusters already created.
In this guide, you will learn to quickly and easily set up a basic infrastructure proof of concept.
My original goal was to design a blueprint for an ‘ideal’ Databricks infrastructure, one that is:
This infrastructure can be expanded upon and modified to fit your exact needs.
The proposed architecture (see below) is complex enough to require automation for the setup and ongoing development of the Delta Lakehouse.
We implement this project as ‘Infrastructure as Code’ for the following reasons:
The two main areas where automation comes into the picture are setting up cloud resources and the release cycle of the Delta Lakehouse.
The first step was to define what an ideal basic infrastructure is.
For this phase, I leveraged an architecture we recently proposed to a client for their data platform design. Rather than synthesizing various possible architectures to find a common denominator, I determined that this recent design could effectively address our first requirement (Consistency).
Additionally, selecting this architecture provides us with a strategic advantage should the client proceed with implementation in the future. 😉
For the purposes of this blog post, I've adapted the architecture into a more generalized design to maintain client confidentiality:

Let’s zoom in on the main elements of this proposal:
It could occur to you to separate the elements of the medallion architecture for a given environment into different Storage Accounts. For this project, I didn’t deem it necessary. Separation is possible, the benefit of such granular division is not apparent. But the design can be easily adapted if business requirements change.
Should all data related to an environment be stored in a single Storage Account? No. But let’s think about it:
More info about physical separation can be found in the Unity Catalog best practices document.
Unity Catalog is solely responsible for the catalog functionality and access control.
The Delta Lakehouse layer should only know about (and use) the data via the three levels of the Unity Catalog namespace. No physical locations should be used in the Delta Lakehouse layer.
In this design, the Delta Lakehouse uses a Databricks platform and it's built via dbt.
Hiflylabs has extensive Databricks consulting experience utilizing dbt for the creation and management of lakehouses on Databricks platforms. To support the lakehouse development with out of box functionalities the dbt component is included in the design. However, it's not a must to use dbt for building a lakehouse - it could be entirely built on Databricks itself, if that's a requirement.
Terraform emerged as the optimal solution for automating cloud resource setup. Given Hiflylabs' prior experience with Terraform for Snowflake infrastructure provisioning, we were confident in its applicability to our current needs. Although the internal project team had limited Terraform experience, we embraced this as an opportunity for skill development.
Note: The following installation steps have worked on my macOS Sonoma (Version 14.4.1). For other operating systems, please refer to the official documentation linked below each software.
Terraform
I installed Terraform using Brew. I opened a terminal and ran the following commands:
$ brew update
$ brew tap hashicorp/tap
$ brew install hashicorp/tap/terraformTo verify the installation I ran:
$ terraform -help
Click here for the official Terraform Installation instructions for other OS’ and troubleshooting
Azure CLI
I also used Brew for installing the Azure CLI. I ran the following in the terminal:
$ brew install azure-cliTo verify the installation I ran:
$ az -h
Follow the official Azure CLI installation instructions if you get stuck.
For Azure authentication I used the Azure CLI.
I ran the following in the terminal:
$ az login
Note: It is enough to authenticate through 'az login' once and then Terraform can use the OAuth 2.0 token for subsequent authentications.
While Terraform code can be consolidated into a single file for basic functionality, we prioritized testing modular code structures to ensure scalability for production-grade implementations.
Note: The code is available on Github—use v_1.0 release for this post.
Structure of the code base
The code base is broken up into two main folders:
Modules
The structure of the modules is the following:
| File name | Explanation |
| README.md | Contains an explanation of the module, what it does, how it works, etc. |
| <module_name>.tf | Contains the resource (*) definitions that the module creates. |
| variables.tf | Declares the variable values that the module uses. |
| required_providers.tf | Specifies the Terraform providers that the module uses - versions can be specified. |
| outputs.tf | Declares the values that the module returns. |
Projects
The structure of the projects is the following:
| File name | Explanation |
| README.md | Contains an explanation of the project, what it does, how it works, etc. |
| <project_name>.tf | Contains the module calls with dependencies that are needed to create the desired infrastructure. |
| variables.tf | Declares the variable values that the project uses. |
| terraform.tfvars.template | A template to help create 'terraform.tfvars'. |
| terraform.tfvars | Contains the value assignment to the variables declared in 'variables.tf'. Note: it doesn't exist in the repo, it needs to be created with your own details. |
| data.tf | Specifies the Terraform data (*) elements that the project uses. |
| required_providers.tf | Specifies the Terraform providers that the project uses - versions can be specified. |
| provider_instances | Declares and configures the provider instances that are used in the project. |
| outputs.tf | Declares the values that the project returns and prints to the screen. |
(*) In Terraform there are two principal elements when building scripts: resources and data sources. Resource is something that will be created by and controlled by the script. A data source is something which Terraform expects to exist.
Variables
The 'variables.tf' file contains the variable declarations together with the specification of the default values. The 'terraform.tfvars' file contains the value assignments to the declared variables. Note: entries in 'terraform.tfvars' overwrite the default values specified in 'variables.tf'.
All the non-sensitive variables contain default values. When there is no entry for a variable in 'terraform.tfvars', the default value is taken.
Variables that are declared as sensitive cannot have default values, so they need to be declared in 'terraform.tfvars' in order to run the code.
Check out the repository
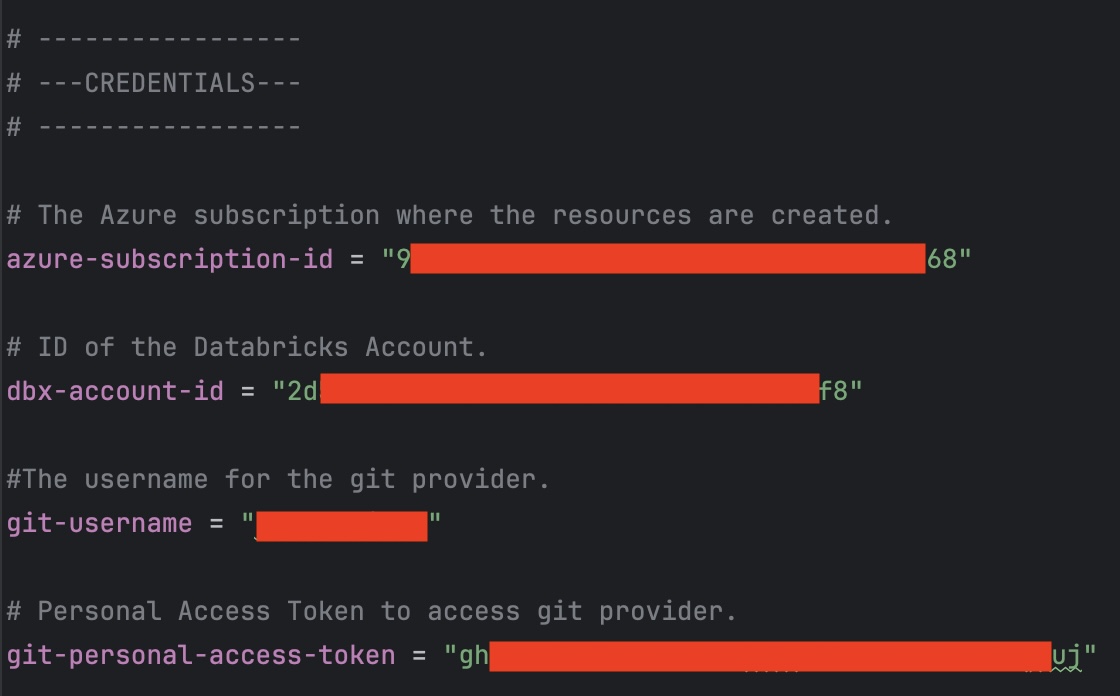
Create and configure 'terraform.tfvars'
Initialize Terraform
Run the script
Terraform Output
Azure Resource Group
module.azure[0].azurerm_resource_group.this: Creation complete after 2s [id=/subscriptions/9869e986-3f70-4d81-9f1d-7a7b29328568/resourceGroups/dbx-terraform-bootstrap]Azure Databricks Access Connector
module.unity-catalog-azure.azurerm_databricks_access_connector.acces_connector: Creation complete after 17s [id=/subscriptions/9869e986-3f70-4d81-9f1d-7a7b29328568/resourceGroups/dbx-terraform-bootstrap/providers/Microsoft.Databricks/accessConnectors/access-connector]Databricks Unity Catalog
module.unity-catalog-azure.azurerm_storage_account.unity_catalog: Creation complete after 24s [id=/subscriptions/9869e986-3f70-4d81-9f1d-7a7b29328568/resourceGroups/dbx-terraform-bootstrap/providers/Microsoft.Storage/storageAccounts/unitistoragedbxterraform]Azure Storage Container for Unity Catalog
module.unity-catalog-azure.azurerm_storage_container.unity_catalog: Creation complete after 1s [id=https://unitistoragedbxterraform.blob.core.windows.net/unitymetastore]Azure Blob Data Contributor Role Assignment
module.unity-catalog-azure.azurerm_role_assignment.unity_blob_data_contributor: Creation complete after 26s [id=/subscriptions/9869e986-3f70-4d81-9f1d-7a7b29328568/resourceGroups/dbx-terraform-bootstrap/providers/Microsoft.Storage/storageAccounts/unitistoragedbxterraform/providers/Microsoft.Authorization/roleAssignments/35f9a12e-0dd4-0282-25e4-24d223-7c3e4f]Databricks Workspace
module.dbx-workspace.azurerm_databricks_workspace.this: Creation complete after 2m25s [id=/subscriptions/9869e986-3f70-4d81-9f1d-7a7b29328568/resourceGroups/dbx-terraform-bootstrap/providers/Microsoft.Databricks/workspaces/dbx-terraform-bootstrap]Databrick Unity Catalog Workspace Assignment
module.unity-catalog-metastore.module.unity-catalog-workspace-assignment.databricks_metastore_assignment.prod: Creation complete after 0s [id=3257333208545686|9d430cc4-e7dd-4b97-b095-9eb24226ac99]Unity Metastore Data Access
module.unity-catalog-metastore.databricks_metastore_data_access.access-connector-data-access: Creation complete after 2s [id=9d430cc4-e7dd-4b97-b095-9eb24226ac99|access-connector]Databricks Repos
module.dbx-repos.databricks_git_credential.ado: Creation complete after 2s [id=764573043456860]
module.dbx-repos.databricks_repo.all["repo_1"]: Creation complete after 7s [id=106725931470002]Databricks Cluster
module.dbx-auto-scaling-clusters[0].databricks_cluster.shared_autoscaling["cluster_1"]: Creation complete after 7m16s [id=0507-085727-ym3yf34v]Terraform Codebase
After running 'terraform apply' the following files/folders were created by Terraform:
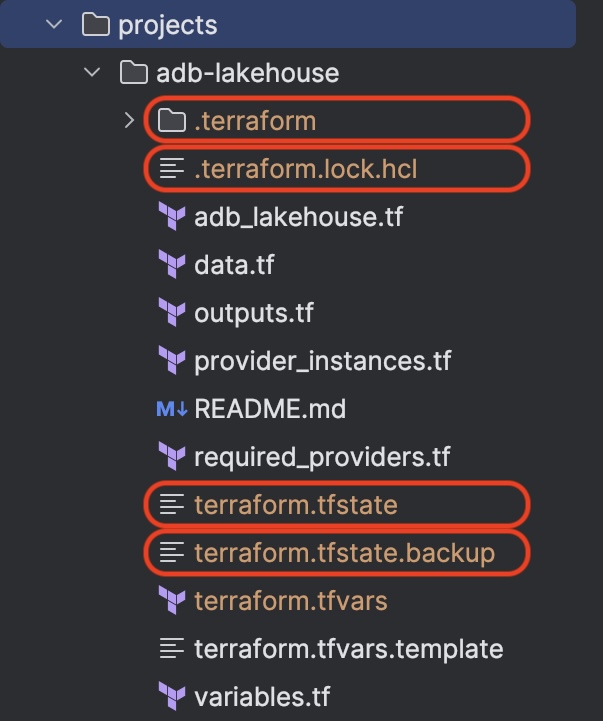
| File/Folder name | Explanation |
| .terraform | The folder is a local cache where Terraform retains some files it will need for subsequent operations against this configuration. |
| .terraform.lock.hcl | Lock file that makes sure that the same infrastructure will be created if multiple users are working. It serves as a central repository for the particular provider and module versions that you have used in your configuration. |
| terraform.tfstate | The content of this file is a JSON formatted mapping of the resources defined in the configuration and those that exist in your infrastructure. |
| terraform.tfstate.backup | Backup of the state file above. |
Azure Resources
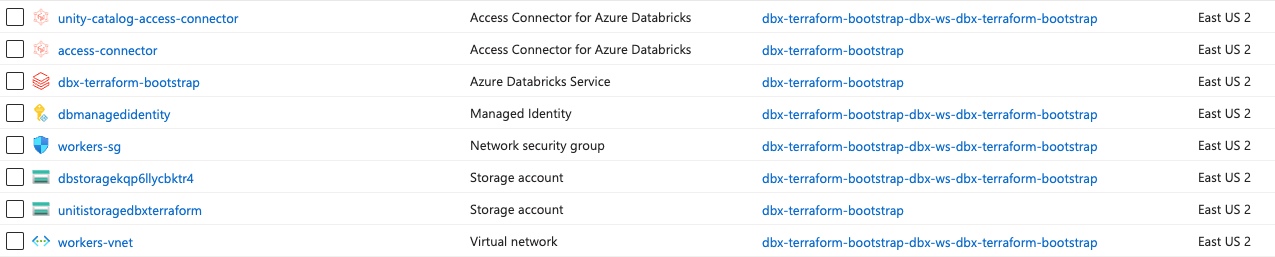
The following Azure resources were created:
Databricks Resources
Workspace with Repo
The specified Github repository was imported
Cluster
The specified auto scaling cluster was created

Unity Catalog
A Unity Catalog was created and assigned to the Workspace
Findings
General experiences
Conditional creation of cloud resources
I was looking for a way to decide if the Azure resource group (or any other resource) should be created or not. I only found a workaround to provide this functionality.
In Terraform we can use conditional statements in the following syntax:
<boolean expression> ? <return value for true> : <return value for false>I solved the conditional creation of the Azure resource group this way:
count = var.create-azure-resource-group ? 1 : 0(source)
When we set the count for a Terraform resource, it will create as many pieces of that resource. In the case above, the conditional statement either sets this value to 0 or 1 - based on the configuration variable. When count is set to 0, the rest of the Terraform code for that resource creation is skipped.
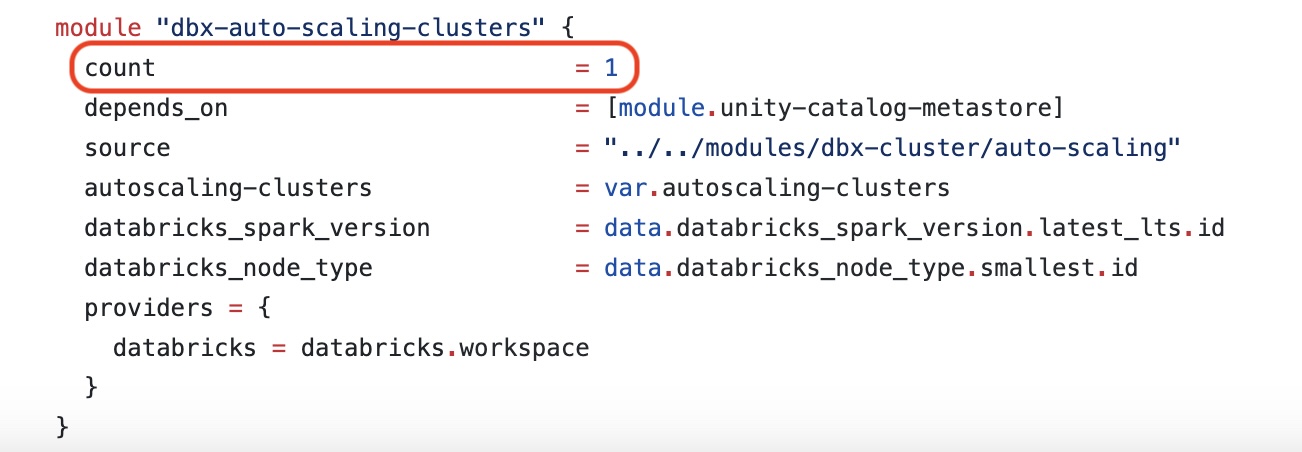
Single vs. Multiple Creation of Resources
Running the Terraform code handled the creation of resources elegantly.
| When something in the code | then Terraform |
| existed | left it untouched |
| changed | recreated it |
| was added | created it |
Everything worked like this until the point I created Databricks clusters via Terraform.
For the clusters however, the behavior has changed: running every terraform apply command created a new Databricks cluster with the same name as before.
My solution to this issue was to set count for the resource.
Unable to destroy an existing Unity metastore
Even though I set force_destroy = true
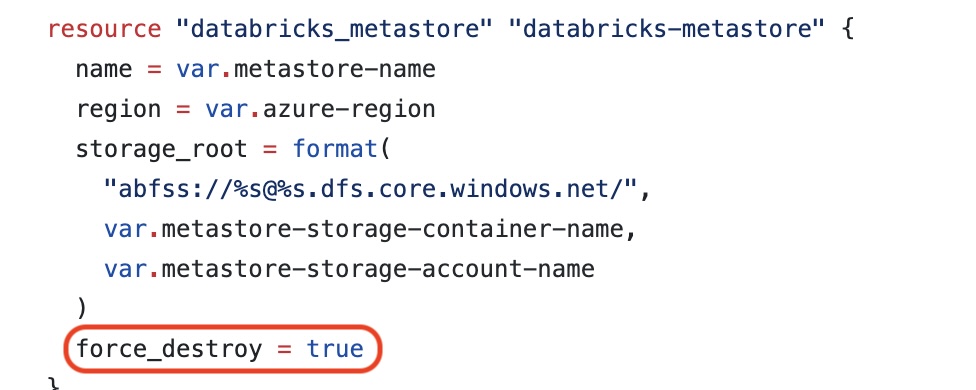
(source) for the Unity Metastore resource, I keep getting the following error message when running 'terraform destroy' – I could not figure out the solution to this problem in time, so I ended up deleting the metastore manually when I needed to.

│ Error: cannot delete metastore data access: Storage credential 'access-connector' cannot be deleted because it is configured as this metastore's root credential. Please update the metastore's root credential before attempting deletion.
│
There are a few more areas we need to consider when developing production code
Terraform proves to be an effective tool for automating cloud resource creation (Infrastructure as Code) in Databricks environments.
While there's a learning curve to writing manageable Terraform code, its support for modular design enhances efficiency and maintainability.
As a data engineer, proficiency in this area is valuable—we’re expected to set up and manage non-production environments (e.g., development, testing).
The investment in automating infrastructure setup through code consistently yields benefits, reducing manual effort and potential errors.
All in all: This approach not only saves time but also improves consistency across environments, facilitating easier scaling and modifications as project requirements evolve.
AI agents are here, and they’re not just suggesting actions. They are taking actions as well, on their own! The question is: who’s governing them?

Humanity has always tried to predict the future. We’re swapping tea leaves for datasets. We explore our collective obsession with AGI timelines, the moving goalposts of superintelligence, and why we ultimately decided to build a scoreboard to keep everyone honest.

Digital twinning allows you to minimize downtime when maintaining large-scale machinery. But it’s not exclusive to gigantic pieces of equipment—even something as small as a coffee machine can showcase its benefits.